Introduction
In the field of deep learning, the standard training paradigm is offline learning. During offline learning 1) parameter updates are mini-batched (i.e., updates from multiple datapoints are averaged together each iteration) and 2) training is performed for multiple epochs (i.e., multiple passes over the training dataset). The goal is to get the neural network to minimize some loss function on a test/hold out set of data as much as possible by the end of training. The tacit assumption behind offline training is that neural networks are trained first on a stored/locally generated dataset, then deployed to perform the task on some new data (e.g., only after AlphaGo was trained did it then compete against professional human Go players in publicly viewed matches).
Though offline learning is currently standard, I’ve recently come to appreciate the importance of online learning, a learning scenario which is distinct in important ways from offline learning. Online learning better describes the learning scenario humans and animals face and it has an increasing number of applications in machine learning. However, it seems to me most researchers in deep learning and computational neuroscience are not working directly or thinking deeply about online learning. Part of the issue may be that the term ‘online learning’ is often not well defined in the literature. Additionally, I suspect many believe the differences between offline and online learning are not mathematically interesting, or they believe that the best performing algorithms and architectures for offline scenarios will also be the best in online scenarios. However, there are reasons to believe this is not quite right. In what follows, I describe what online learning is, how it is different in interesting ways from offline learning, and why neuroscientists and machine learning researchers should care about it.
What it is Online Machine Learning?
First, it should be said that ‘online learning’ is not synonymous with ‘continual learning‘. Continual learning is the learning scenario where a model must learn to reduce some loss across multiple tasks that are not independent and identically distributed (i.i.d) (Hadshell et al., 2020). For example, it is common in continual learning scenarios to present tasks sequentially in blocks, such that the model is first presented with data from one task, then the data from a second task, and so on. The difficulty is in preventing the model from forgetting previously learned tasks when presented with new ones. Continual learning is a popular topic in deep learning, and many high-performing solutions have been proposed.
Formal work on online learning often makes the assumption data is i.i.d, although combined online-continual learning scenarios have also been worked on (e.g., Hayes et al. 2022). Informally, online learning can be described as having at least the following properties: 1) each training iteration a single datapoint is presented to the model, 2) each datapoint is presented to the model only once (one epoch of training), and 3) the model’s goal is to minimize the loss averaged over every training iteration (called the cumulative loss, defined below). For examples of classic/widely cited papers that use this description, see Crammer et al. (2006), Daniely et al. (2015), and Shalev-Shwartz (2012) . This is opposed to offline scenarios where multiple datapoints (i.e., mini-batches or batches) of datapoints are presented each iteration, each datapoint is presented multiple time (i.e., multiple epochs of training), and the model’s goal is to minimize the loss on some hold-out/test data as much as possible by the end of training.
Formally, the online learning objective is the cumulative loss. Consider the scenario where a model is given a single datapoint 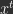 and prediction target
and prediction target  each iteration
each iteration  . The model, parameterized by
. The model, parameterized by  , must try to predict given as input. After the prediction is outputted, feedback is provided in the form of a loss
, must try to predict given as input. After the prediction is outputted, feedback is provided in the form of a loss 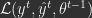 , where
, where 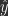 is the prediction generated by given . In this case the cumulative loss is:
is the prediction generated by given . In this case the cumulative loss is:
 .
.
The cumulative loss is the average loss produced by the model during training on each data point as it was received in the sequence. In order to achieve a good cumulative loss the model not only must eventually perform well but must improve its performance quickly, since the losses produced at early iteration are factored into the final cumulative loss. A similar loss called the ‘regret’ is also sometimes used in online scenarios. The regret is just the cumulative loss achieved by the optimal parameters (e.g., parameters pretrained offline), minus the cumulative loss.
Compare this to offline learning, where the loss is averaged/summed over a hold-out/test dataset that is not used to train the model:
 ,
,
where 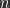 refers to the datapoint in the test set and
refers to the datapoint in the test set and  are the parameters at iteration
are the parameters at iteration  . The test loss describes how well the model is doing right now at the current training iteration . Thus, minimizing the test loss only requires that the model perform well eventually, by the end of training. It does not factor in how how the model performed at earlier training iterations. For the same reasons, the cumulative loss is distinct from the training loss, which describes how the current parameters perform on the entire training dataset.
. The test loss describes how well the model is doing right now at the current training iteration . Thus, minimizing the test loss only requires that the model perform well eventually, by the end of training. It does not factor in how how the model performed at earlier training iterations. For the same reasons, the cumulative loss is distinct from the training loss, which describes how the current parameters perform on the entire training dataset.
Some examples of online learners may include spam bots, surveillance devices, robots, autonomous vehicles, animal brains, and human brains. In all of these cases, the models are often assessed by how well they perform/learn while they are being deployed, and in all of these scenarios input data is generated one at a time, and no two datapoints are exactly the same (due to noise and the infinite possible varieties of inputs these models could receive from the real world).
In addition to the properties listed above, online scenarios often face other problems that are not standard in offline scenarios like concept drift and imbalanced data. Concept drift refers to the event where the underlying processes generating the data change (e.g., a robot moves to a new environment) (for review see Lu et al. (2018)). Imbalanced data refers to datasets where there are uneven numbers of training instances across classes/tasks (e.g., a robot in the desert may see 1,000 rocks for every one cactus). Dealing with these two scenarios are common topics in the online learning literature (e.g., see Hayes et al., (2022)).
The Mathematical Distinction between Online and Offline Learning Matters
I suspect some machine learning researchers assume that any learning algorithm that performs well in offline learning scenarios will also perform well in online learning scenarios. This judgment is not necessarily true and the mathematical distinction between the two learning scenarios makes clear why. Here are two important distinctions:
1. The online learning objective places more emphasis on reducing the loss quickly than offline learning objectives. Minimizing cumulative loss requires a learning algorithm not only update the model to perform well eventually, but also to perform well early in training. Thus, cumulative loss is affected by the rate at which the learning algorithm reduces the loss. Test loss is not directly affected by the speed of the algorithm. The test loss only cares how well the model is performing at the end of training (or the iteration where it is measured), and usually one trains long enough for the model to converge. Thus, a slow algorithm that reduces test loss well in offline scenarios may not reduce cumulative loss well in online scenarios.
2. Convergence guarantees are less important in online learning scenarios than offline learning scenarios. In offline scenarios, it is typically desired that a learning algorithm be guaranteed to converge to a minimum of the test loss after some number of training iterations (and epochs), since models can often be trained to convergence in offline scenarios. However, in online scenarios convergence is not always achievable, since the model is only doing a single pass through the data and in some cases there is not enough data for the model to converge. This is also the case with infinite/streaming data scenarios when concept drift occurs, and the model only trains for a finite period of time before the data distribution changes. In online scenarios, it may be desirable to sacrifice convergence guarantees for gains in training speed and low computation overhead. An example of an algorithm that is not guaranteed to converge but performs well in online scenarios are winner-take-all clustering models (e.g., see Hayes et al. (2020, 2022) and Zhong (2005) for example of online winner take all clustering. See Neal and Hinton (1998) for discussion of why winner-take-all clustering lacks the convergence guarantees of expectation maximization).
These differences imply that not all good solutions to the offline learning problem are good solutions to the online problem. We can, for instance, imagine an algorithm that reduces the loss slowly but consistently converges to very good local minima when trained with large mini-batches for many epochs. This algorithm would be great for offline learning, but is non-ideal for online learning. Interestingly, the standard learning algorithm used in deep learning is backpropagation which implements stochastic gradient descent (SGD). It is well known that SGD finds very good local minima in deep neural networks in offline training but trains slowly.
Understanding the Brain Requires Understanding Online Learning
Here’s an argument for why computational neuroscientists should care about online learning:
- Humans and animals learn online during most of their waking lives. It therefore seems safe to assume our brains evolved learning algorithms that deal well with the online scenario specifically.
- Solutions to the offline learning scenario will not always be the best solutions to the online scenario, for reasons noted above.
- Therefore, computational neuroscientists interested in understanding learning in the brain should focus on developing theories of biological learning that are based on good solutions to the online scenarios, without assuming that solutions to the offline scenario will work well too.
Again, backpropagation, which implements SGD, is not clearly the best solution to online learning in deep neural networks. It is currently, in practice, the best solution we have for offline learning, but again SGD is slow and therefore may be non-ideal for online scenarios. There is thus some reason to look to other optimization procedures and algorithms as possible explanations for what the brain is doing.
Online Learning as a Standard Approach in Neuromorphic Computing
Neuromorphic chips are brain-inspired hardware that are highly energy efficient. They typically implement spiking neural networks and have similar properties as the brain. These chips are ideal for robots and embedded sensors interacting with the real world that have tight energy constraints (e.g., finite battery power). Notice these are the same scenarios where online learning would be especially useful, i.e., an embedded system interacting with the real world in real time. Thus, there is motivation from a neuromorphic computing point of view to think hard about the online learning problem. Much work on spiking networks, it seems to me, is focused on adapting backprop to spiking networks. However, for reason discussed above, assuming backpropagation is the ideal/gold-standard solution for online learning to here is not obvious. It may therefore be useful to look to other optimization methods or to develop new ones specifically for online learning on neuromorphic chips.
References
Crammer, K., Dekel, O., Keshet, J., Shalev-Shwartz, S., & Singer, Y. (2006). Online passive aggressive algorithms.
Daniely, A., Gonen, A., & Shalev-Shwartz, S. (2015, June). Strongly adaptive online learning. In International Conference on Machine Learning (pp. 1405-1411). PMLR.
Hadsell, R., Rao, D., Rusu, A. A., & Pascanu, R. (2020). Embracing change: Continual learning in deep neural networks. Trends in cognitive sciences, 24(12), 1028-1040.
Hayes, T. L., & Kanan, C. (2020). Lifelong machine learning with deep streaming linear discriminant analysis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops (pp. 220-221).
Hayes, T. L., & Kanan, C. (2022). Online Continual Learning for Embedded Devices. arXiv preprint arXiv:2203.10681.
Lu, J., Liu, A., Dong, F., Gu, F., Gama, J., & Zhang, G. (2018). Learning under concept drift: A review. IEEE Transactions on Knowledge and Data Engineering, 31(12), 2346-2363.
Neal, R. M., & Hinton, G. E. (1998). A view of the EM algorithm that justifies incremental, sparse, and other variants. In Learning in graphical models (pp. 355-368). Springer, Dordrecht.
Shalev-Shwartz, S. (2012). Online learning and online convex optimization. Foundations and Trends® in Machine Learning, 4(2), 107-194.
Zhong, S. (2005, July). Efficient online spherical k-means clustering. In Proceedings. 2005 IEEE International Joint Conference on Neural Networks, 2005. (Vol. 5, pp. 3180-3185). IEEE.