by Nick Alonso
The standard way of measuring performance in deep learning is through a test loss: a neural network is trained to perform some task, and the goal is to get the network to reduce the loss as much as possible on a subset of the data that is not presented during training (i.e., the test set). A low test loss means the model performs the task well when applied to new data points that were not previously observed. The test loss, however, does not account for how quickly the model learns. It provides a measure of how well the model is performing at the time the test is performed but ignores the time and effort it took the model to get to that performance.
This way of measuring performance is well and good if our only interest is to have some model eventually reach a desired state of competence. However, we often have an interest in the amount of computation, energy, and time costs associated with training the model. Further, this loss measure seems to me to be largely indifferent to an essential aspect of intelligence: learning efficiency. Simple examples and existing theories of intelligence make clear that intelligent systems are not just those that eventually reach some state of high competence on some set of tasks. They are those that also do so efficiently, where ‘efficiency’ roughly corresponds with the amount of data the model needs to learn a task, which is also correlated with training speed, energy costs, etc. If this is right it would have interesting implications, e.g. recent versions of GPT are not as intelligent as they may seem on first impression. These models may be incredibly competent at generating human sounding language in response to prompts and incredibly knowledgeable, but they are just too data hungry to be near the intelligence of more efficient learners, like humans and some complex animals.
Why does learning efficiency matter for intelligence? Here’s one example. Most people think child prodigies are highly intelligent. Consider the chess prodigy who is playing competitively with professionals three times his age, or the child who graduates high school at age nine. Why is it so obvious these children are smarter than most others? It is not the knowledge and skills they have. That is, it is not their competence at certain tasks that is so impressive. Though the chess prodigy may be very good, there exist many professionals who have equal or better skill than him, and it is unlikely the 9 year old high school graduate has more factual knowledge or skills than others who have graduated high school and college who are much older. The reason we universally acknowledge the intelligence of these children is because of how efficiently they learn compared most other people. They acquire more knowledge and skill from less data and less practice than just about everyone else. We admire not the end result, but the ease and speed with which they achieved the end result. Thus, any theory of intelligence must account not just for knowledge/competence/skill, but also the efficiency with which that knowledge and skill is acquired. Examples like these have motivated some researchers to develop formal theories of intelligence that explicitly take this intuitive notion of efficiency into account (e.g., [1]).
The test loss measure of performance, therefore, completely misses a crucial ingredient of intelligence. It is not sensitive to how efficiently the model learns. How might we better track intelligence? We could begin with a formal theory of intelligence to develop a measure. Some of these theories may be a bit cumbersome, however, in practice since many require expensive computations, which may limit the ability to frequently track a model’s progress. Further, these theories make very specific claims, and do not all agree, which raises the question of, which theory, if any, gets all the details right?
Alternatively, I suggest the cumulative loss may provide a simpler, easy to compute method that better tracks intelligence than the test loss. I do not claim the cumulative loss is a measure of intelligence, but I think it may better correlate with intelligence than the test loss. The cumulative loss is simple. Let 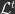



That is, the cumulative loss is just the losses computed at each training iteration averaged together. Notice that this loss is very easy to compute and is task general. However, it is sensitive to how the model performs early in training. Consider two models/neural networks. Model 1 learns slowly so that it has high loss early in training, while model 2 trains quickly. Both converge to the same loss by the end of training. As desired, the second model (the more efficient learner) would have a lower (better) cumulative loss since it has lower losses early in training and these losses are incorporated into the cumulative loss.
Now consider the case where both models learn with equal efficiency (e.g., both converge or nearly converge after the same number of updates) but model 1 converges to a better loss. Model 1 will have a lower cumulative loss in this case, which seems to correctly track the model we would say is more intelligent.
Finally, consider the case where model 1 converges much more quickly than model 2, but model 2 converges to a better loss by the end of training. Which model is more intelligent? My intuitions are that it is not clear, which is also true of the cumulative loss: it is not clear from the details given which model would have better cumulative loss. More details are needed on how much more quickly model 1 reduced the loss compared to model 2, how much better the performance of model 2 was by the end of training than model 1, and how long the two trained for. Most people I suspect will likely have mixed feelings in these cases about which model is more intelligent, which means it is a theoretical gray area. In such cases, our loss measure, if it is to track intelligence, should measure the two models as having similar losses. This is just what the cumulative loss will end up doing, which is why we cannot tell which model has a higher cumulative loss from the details given (more details are needed because the two will have similar cumulative losses in this case). It would be interesting empirically to see how well this loss measure tracks common judgments and various theories of intelligence, but just from this bit of analysis it is clear it may be a good start.
References
Chollet, F. (2019). On the measure of intelligence. arXiv preprint arXiv:1911.01547.
