Nick Alonso
A famous philosophical thought experiment imagines Mary, a neuroscientist, who knows all the physical, biological, and functional facts about the human color vision system. Crucially, Mary has never had a conscious experience of color until some point after she acquires all of this neuroscientific knowledge. This raises a question: when Mary consciously experiences color for the first time, does she learn something new about color experience? The thought experiment is meant to support Dualism, the view that consciousness is non-physical in some way.
The purpose of this blog, however, is not to discuss this well-trod debate about Mary and Dualism. Instead, below, I imagine a variant of the Mary thought experiment that is meant to support Illusionism.
What is Illusionism? ‘Phenomenal realists’ say consciousness has a ‘what-it-is-likeness’, ‘phenomenality’, ‘phenomenal character’, or ‘subjective character’ (henceforth, just phenomenal character). What it is like to experience the color red from the first person point of view, for example, is the phenomenal character of the red experience. Realists say explaining how and why consciousness with phenomenal character arises from the brain is a very hard problem, maybe the hardest in all of science. Illusionists, on the other hand, accept that it surely seems as if this phenomenal character exists but deny it actuality does, and, if there is no phenomenal character, there is no hard problem.
Most find Illusionism to be highly implausible. The argument I present below is meant to make Illusionism more palatable. The argument uses a hypothetical scenario to present a kind of dilemma for phenomenal realists — it seems to force phenomenal realists to accept one of two difficult to defend conclusions. I am still unsure how challenging this dilemma is for Realists, but I am convinced it is non-trivial. In any case, the hypothetical scenario is an interesting one to think through.
I have not found previous work that discusses a scenario exactly like one I describe below, though a few years ago Eric Thomas presented a similar thought experiment. Thomas imagines a non-conscious alien scientist studying cats. His thought experiment begins with phenomenal Realist assumptions and uses the thought experiment to present an argument for Dualism. The thought experiment I present below, on the other hand, imagines a non-conscious scientist studying humans. My argument begins agnostically about the Realist-Illusionist debate and is used to present an argument for Illusionism.
The Non-Conscious Neuroscientist Scenario
Imagine a neuroscientist, Mary, who is non-human. We can, for example, imagine she is an alien or AI. Despite being non-human, Mary is highly intelligent and cognitively similar to humans in most ways except for one: unlike humans, Mary does not have phenomenal experience herself nor does she have any intuition that she has mental states with phenomenal character.
Mary has an intuitive psychology not unlike humans’, which disposes her to represent her own and others’ minds as consisting of states similar to what we call beliefs, desires, perceptions, intentions, etc. However, she understands these states in a way that is independent of any relations to phenomenal character. She may, for example, understand them purely in terms of their functional aspects, i.e, their causal relations to each other and behavior, but Mary has no intuitive sense these mental states have any special phenomenal character.
In addition to an intuitive psychology, Mary has extensively studied her own brain and human brains, so much so that she has a complete knowledge of all the physical-functional facts about her own and human brains. She knows all the facts about their physical-biological properties from the cellular level down to the level of atoms. She knows all of their computational-functional properties, from abstract cognitive levels down to fine-grained neural levels.
This knowledge, of course, includes a complete physical-functional understanding of why humans tend to say they have mental states with a mysterious phenomenal character. (For simplicity, I’ll call verbal reports about one’s own mental states with phenomenal character ‘p-reports‘.) Mary knows all the cognitive-computational mechanisms that dispose humans to make p-reports and she knows how these cognitive processes are implemented in the human brain. Mary has even identified the particular cognitive-computational states and processes that seem to be at the root of the human tendency to generate p-reports, i.e., the main source(s) of human p-reports.
What Should Mary Believe about Consciousness?
The first question to consider is what should Mary believe (emphasis on ‘should’) about the nature of, what people call, phenomenal consciousness? In particular, should she believe people have mental states with phenomenal character or not?
Assume Mary begins agnostically. She initially assigns equal probability to both Realism and Illusionism. She should now only adjust her credences appropriately in response to relevant rational argument and empirical data.
So, what arguments and data might there be for Mary to increase her credence in Realism?
The first point to make is that just because people insist they have experiences with phenomenal character is not evidence that they actually do. People’s p-reports are empirical data that are equally as consistent with Illusionism as they are with Realism. Illusionism, like Realism, predicts people should say they have conscious experience with mysterious phenomenal character and write books about these mysterious properties of consciousness, and so on. In order for p-reports to be evidence against Illusionism, they would have to be more probable under Realism than Illusionism, but they are not.
Consider a related point: Mary has a complete consciousness-neutral, physical-functional description of the causes of p-reports that does not assume anything philosophically mysterious like phenomenal character exists. This description will sufficiently explain why humans tend to generate p-reports in the sense the p-report generating processes it describes will entail that such behaviors should come about, just as any human behavior is entailed by some prior physical-functional state of the brain and body. Therefore, phenomenal character is not needed to provide a sufficient causal explanation of p-reports in this sense, and cannot in this sense provide Mary with reason to believe phenomenal character exists.
The second point to make is that Mary’s knowledge of the human brain does not appear to provide reason for her to increase her credence in Realism. To see this, consider the possibility that the explanatory gap exists. The explanatory gap is the view that physical-functional facts about the brain do not entail anything in particular about phenomenal character. For example, it does not seem that certain physical-functional states of the visual cortex, say, should entail the existence of a color experience with particular phenomenal character rather than some other experience or no experience at all. Many philosophers believe this gap exists.
If we assume this gap exists, from Mary’s point of view, there would be nothing in particular about phenomenal character, including the probability that it exists, that is implied from her complete physical-functional knowledge of the human brain. If the explanatory gap exists, any physical-functional facts about the brain cannot provide Mary with reason to increase her credence in Realism.
Next, consider the case where the explanatory gap does not exist — physical-functional facts about the brain do entail facts about the phenomenal character of experience. In this case, one might think Mary would have reason to favor Realism: if certain physical-functional facts about the brain entail certain conscious states with certain phenomenal character should exist, and Mary understands these entailments, she would realize phenomenal character must exist.
However, it is hard to make sense of this idea. How could Mary even understand/conceptualize phenomenal character in the same way humans do? First, unlike humans, she cannot understand phenomenal character introspectively, since she has no experience herself. Mary, therefore, cannot understand phenomenal character under the common description “what it is like to have some experience from the first-person point of view”. Second, phenomenal character would not be mysterious to her. If certain physical-functional facts entailed that certain conscious states with certain phenomenal character exists, and Mary knows and understands the details of these entailments, she should not get the feeling there is anything mysterious or deeply problematic about phenomenal character. She would not understand phenomenal character as “that aspect of consciousness that is deeply hard to explain in third-person, physical-functional terms” because no aspect of consciousness would be deeply problematic to explain in physical-functional terms from her third-person point of view.
Any concept of consciousness and phenomenal character cognizable by Mary, that she could deduce from her knowledge of the human brain, would seem to be a deflated version of the conception used by human phenomenal realists, in these ways. Instead, Mary’s resulting deflating concept of phenomenal character would seem to perfectly consistent with the concepts of consciousness used by Illusionists, who define consciousness in some physical-functional way without reference to any introspectable, mysterious properties.
Thus, in any case, whether there is or is not an explanatory gap, physical-functional facts about the brain do not seem to provide Mary reason to believe mental states with phenomenal character (in the realist sense) exist.
(Note also there is a third possible scenario, where there is no explanatory gap but Mary does not understand the entailments between physical-functional brain facts and phenomenal character. In this case, Mary would face the same challenge as the case where there is an explanatory gap — she would not know that or how physical-functional facts about the brain entail facts about consciousness with certain phenomenal character and, therefore, these entailments would not provide her with reason to believe any phenomenal character exists.)
So, empirical knowledge about human verbal reports and the physical-functional properties of the human brain do not provide Mary with reason to increase her credence in Realism. If data about human behavior and the brain cannot do so, what can? The remaining possibility is a priori philosophical arguments against Illusionism.
The challenge with this approach is that in order for such arguments to provide reason for Mary to update her beliefs, they cannot assume introspective access to consciousness. For example, unlike people, Mary cannot by swayed by the common argument ‘I know conscious states with a mysterious phenomenal character exists because I observe they exist in my own mind‘ or ‘If I know anything it is that I am having certain experiences right now with certain phenomenal character‘. Mary has no such introspective access to conscious experience with phenomenal character, so such arguments should not persuade Mary. Furthermore, Mary should not be swayed by arguments that appeal to common sense since it is not common sense to Mary (or any other intelligences like Mary) that phenomenal character exists.
What philosophical arguments could phenomenal realists appeal to that do not assume introspective access to phenomenal consciousness? It is unclear at best what these would be. It is far outside the scope of this blog to survey all of the various criticisms of Illusionism here one by one, but I think the main challenge for Realists is that many, if not most, of the prominent criticisms of Illusionism appeal to introspection in some way. If an argument requires an introspective understanding of consciousness, should be ineffective at swaying Mary who has no introspective understanding of phenomenal consciousness.
For example, one approach, taken by Eric Schwitzgebel is to try to define phenomenal consciousness in an “innocent” way that does not explicitly refer to phenomenal character or other mysterious properties. Instead, it just defines consciousness by whatever property is shared by the mental states people call conscious states. By removing the reference to phenomenal character in the definition, Illusionist views that make direct claims about phenomenal character can be avoided.
The issue here is the shared property that Schwitzgebel seems to have in mind is one that is identified upon introspection. Phenomenal consciousness, under his definition, “is the most folk psychologically obvious thing or feature that the positive examples possess and that the negative examples lack”. Such a folk-psychological definition would therefore necessarily not involve knowledge learned by scientifically studying the physical-functional facts about brain. Instead, this folk-psychological definition would rely on feature(s) identified in the intuitive common fashion, i.e., via introspection.
However, under such a definition, Mary cannot understand what humans are referring to by introspecting her own mind, since she does not introspect anything she is disposed to call phenomenal conscious states. Mary’s only way to try to identify what humans are referring to would be to study human judgments/verbal reports about consciousness and develop a scientific theory of what it is they are referring to when introspecting and reporting about phenomenal states. For example, if there is some physical-functional state of the brain (e.g., a source of p-reports) that tracks these judgments well, she could use this to develop a scientific, third-person description of what people are referring to when they claim to be introspecting phenomenal character.
However, Mary’s resulting concept of phenomenal consciousness would seem to be consistent with Illusionism. Whatever physical-functional properties Mary identifies would not be deeply mysterious — they would not resist objective, physical-functional explanation from Mary’s point of view since they are themselves physical-functional properties.
This seems to leave us in the same position as before: whatever Mary can try to identify with what people call phenomenal states would seem to be something that leads to a deflated, non-mysterious concept of consciousness totally consistent with Illusionism. Her understanding of consciousness would not lead her to believe there is a hard problem of consciousness. It would not lead her to think consciousness is any different than any other cognitive process.
While there are other anti-Illusionist arguments, I suspect most will somehow require an introspective understanding of consciousness, through some introspective reference to ‘this’ or ‘that’ aspect of consciousness. Since Mary cannot understand such properties introspectively, she can only try to understand them from the outside by trying to explain the associated human verbal reports by their neural-cognitive causes. She can always develop some physical-functional explanation for the reports, but such an explanation will not describe anything that is mysterious, that resists objective, physical-functional explanation. Whatever understanding/descriptions Mary ends up with will leave her with little reason to believe in human mental states with some mysterious phenomenal character.
Another issue for Realists is that there exists a priori philosophical arguments in favor of Illusionism that do not depend on any introspection at all, such as Chalmers’ evolutionary debunking arguments and simplicity arguments in favor of Illusionism. Debunking arguments argue that there is an evolutionary explanation of why humans tend to make p-reports that does not assume they are true, and thus if they are true there would be some epistemic luck, which is implausible. Therefore, the best conclusion is p-reports are false. Simplicity arguments point out Illusionism is simpler than Realism in that it assumes fewer entities exist than Realism does, and Illusionism does not need to assume anything else exists to causally explain all observable physical-functional facts (due to causal closure of the physical universe). In this sense, Illusionism should be preferred.
Importantly, neither of these arguments make any references to introspection. Chalmers’ debunking arguments only make claims about human behavioral dispositions, evolution, and beliefs. Simplicity arguments only makes a simple point about the number of entities each theory claims exist and the causal closure of physics.
Mary’s cognitive set-up, that of having no phenomenal states, seems to remove the force from many common anti-Illusionist arguments, but it does not seem to remove any force from pro-illusionist arguments. This suggests that a priori philosophical arguments should, at least, not alter Mary’s credences, and possibly even sway Mary’s credences in favor of Illusionism.
Mary’s Dilemma for Realism
Now, we come to the second question: why should we, humans, conclude anything different than Mary?
As far as I can see, Realists have two options:
Option 1: They can disagree with the points made in the last section and argue Mary should not conclude Illusionism is at least as plausible as Realism. Instead, Mary should conclude Realism is more plausible. For the reasons previously mentioned, this argument seems challenging.
Option 2: Realists can argue that while Mary should conclude Illusionism is at least as plausible as Realism, humans should conclude Realism is more plausible than Illusionism. Taking this line of reasoning would accept that Mary’s reasoning is valid, but it would argue Mary lacks certain justification that humans have for believing Realism. A challenging question for those taking this option is the question of what this justification is?
There are a few ways Realists might try to answer this question. A simple answer for the Realist would take a Dualist approach and say Mary lacks knowledge of non-physical properties of consciousness. Mary’s mind has no such properties so she cannot access them introspectively, nor can she gain knowledge of them by studying the physical brain. Human minds to have non-physical properties which they can access upon introspection, and therefore humans have some knowledge/justification for believing phenomenal Realism that Mary lacks. The problem with this Dualist approach, is that just about every scientist and philosopher would want to avoid such views, given all the well-known problems that come with Dualism.
Another possible response from Realists would be to simply stipulate people have some special, certain knowledge of phenomenal character gained through introspection of their conscious states (whether they are physically reducible or not). However, Illusionists, like Dan Dennett and Keith Frankish, have pointed out now for decades that such views lack good explanation. If an individual claims some special introspective knowledge or justification for their belief in phenomenal states, through statements like “I have privileged, certain knowledge of my own experiences and their phenomenal characters”, they have to define and explain the concepts they use, such as what the “I” is, what the “phenomenal character” is, and how the special knowledge relation between the two works.
Some philosophers like Chalmers have tried to make direct responses to challenges like this one from Illusionists. However, they make controversial assumptions. For example, here’s part of Chalmers’ response to related challenge posed by Keith Frankish
“In my view a (non-Russellian) dualist should probably endorse primitive subjects, holding that fundamental phenomenal properties are instantiated by fundamental entities (a kind of entity dualism or substance dualism).” (Chalmers, 2020)
This response falls back on Chalmers’ Dualist assumptions, which most researchers would find highly unpalatable.
What is needed for the Realist is some explanation of introspection that does not use the word “I” and does not assume controversial views like Dualism. One option of this sort would appeal to a mental state with a special relation to consciousness. For example, philosophers often appeal to the idea of ‘phenomenal concepts‘, which are special concepts that are used during introspection to represent and think about consciousness and its phenomenal character. These concepts, the idea goes, have some special direct relation to the consciousness, but the way these concepts work can be explained in physical-functional terms. Phenomenal concepts are typically used to counter dualism by providing an explanation for how an explanatory gap could exist without there being an actual metaphysical gap between the physical-function brain and consciousness: phenomenal concepts represent consciousness in a distinct way from descriptive concepts that represent the physical-functional properties. This creates a psychological gap between two kinds of mental representations of consciousness that leads to the explanatory gap. Thus, there is a physicalist (non-dualist) explanation for how an explanatory gap exists.
In the present context, the proponents of the phenomenal concept strategy could use the idea of phenomenal concepts to say something like Mary lacks consciousness and phenomenal concepts. Phenomenal concepts are usually described as having some direct relation to consciousness, so there would likely be some story here about how this direct relation provides people with justification for believing Realism is more plausible than Illusionism, which Mary, not having phenomenal concepts, would lack.
There are several issues with this approach. First, a challenge for phenomenal concept-like strategies is that it is not enough to argue that it is possible for such phenomenal concepts (with special relations to consciousness that justify Realism) to exist. One would have to argue it is more probable than not that they do exist. Remember, we are asking why humans should assign more credence to Realism than Illusionism, rather than just assigning 50/50. To do this, it is not enough to say there is possibly some special phenomenal concepts that provide humans with justification for assigning more credence to Realism, since the mere possibility of such concepts is consistent with a 50/50 assignment of credences.
As far as I can tell, however, the best that proponents of the phenomenal concept strategy have done is show it is only possible phenomenal concepts exist. There isn’t exactly an empirical research program around these ideas that have provided empirical evidence for their existence along with their special epistemic relations to consciousness.
Second, a key component of the phenomenal concept strategy is that such concepts can be explained in completely physical-functional terms. However, if such concepts are fully understandable in physical-functional terms, then Mary will understand everything about them since she knows all the physical-functional facts about the brain (!), including how and in what way they provide humans with justification for believing Realism. But now there is a contradiction. Remember, we are considering how Realists could defend position 2 — the view the Mary should be pro-Illusionist, but humans should be pro-Realist. However, if Mary has knowledge of the same facts that justify Realism for humans, then she will have access to such justification too. Thus, this phenomenal concept approach does not seem compatible with option 2.
Nor does this strategy seem able to defend option 1, the view Mary should place more credence on Realism. Let’s say Mary learns of the special epistemic properties phenomenal concepts provide humans for believing in Realism. What are these? It is just hard to imagine what this special epistemic properties could be, even if phenomenal concepts exist. Maybe something like phenomenal concepts exists that explains why people tend to have dualist intuitions and intuitions there is an explanatory gap. But, this is distinct from the claim these concepts also provide some special knowledge of phenomenal character. What is needed is reason to believe these concepts have something more that involves special epistemic justification for Realism. But, why think these concepts have some special properties that would justify believing in the hard problem and mysterious things like phenomenal character? It is not obvious. The only way I could see a Realist defending this view would be to beg the question, by assuming the existence of phenomenal character, then proceeding to explain some epistemic relation it has to phenomenal concepts.
Let’s consider one final possible response from Realists. Some Realists might argue it is simply obviously true that human’s have knowledge of phenomenal character and it is so obvious stipulation is sufficient to justify this position. The burden is instead on Illusionists to explain why it is insufficient, just as one might be required to explain why something we take to be basic data or a widely held axiom should not, in fact, be considered so.
But, the Mary scenario does seem to reverse this burden. Remember, option 2 for Realists argues Mary should conclude Illusionism is at least as plausible as Realism, but humans should conclude Realism is more plausible. Does this position not cry out for an explanation? What knowledge/justification do humans have to believe in phenomenal character that Mary lacks and how do humans get it? How can it be that Mary knows so much (she knows all the physical-functional facts about the brain, remember) and reasons in a valid manner, yet she is somehow incorrect in her conclusions, while humans are correct? This requires a coherent explanation from Realists.
Conclusions
In summary, this thought experiment presents a kind of dilemma for Realists. It seems Realists must choose between one of two challenging positions:
- Position 1: Mary should favor Realism over Illusionism. The difficulty here is 1) any behavior data Mary can observe is equally consistent with Realism as it is with Illusionism, 2) any brain data Mary can observe provides her with no clear reason to believe phenomenal character exists, and 3) the fact Mary does not introspect phenomenal experience seems to, at best, complicate anti-Illusionist philosophical arguments and, at worst, remove most of their force.
- Position 2: Mary is correct in concluding Illusionism is at least as plausible as Realism, but humans should favor Realism due to some special knowledge/justification they have that Mary lacks. The challenge here is in explaining how people acquire this special knowledge/justification that Mary lacks. The claim Mary can both be reasoning correctly yet be wrong begs for an explanation beyond just simple stipulation that people know something she doesn’t, but Realists have yet to develop any consensus around an argument as to why we should believe that humans have some special introspective knowledge/justification for believing in phenomenal character.
If Realists cannot meet these challenges, then it seems we must agree with Mary and accept Illusionism is at least as plausible as Realism. In other words, we must take Illusionism seriously.
If there is some counter-argument, criticism, or anything else you think I have missed, I would love to hear it! Please post in the comments.


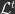 be some loss measure computed at training iteration
be some loss measure computed at training iteration  given the data at
given the data at  computed from the previous iteration. The cumulative loss is just
computed from the previous iteration. The cumulative loss is just
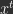 and prediction target
and prediction target  each iteration
each iteration 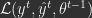 , where
, where 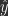 is the prediction generated by
is the prediction generated by  .
. ,
,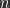 refers to the datapoint in the test set and
refers to the datapoint in the test set and  are the parameters at iteration
are the parameters at iteration  . The test loss describes how well the model is doing right now at the current training iteration
. The test loss describes how well the model is doing right now at the current training iteration 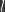 represented as a column vector
represented as a column vector 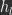 and weights
and weights  that propagate signals from layer
that propagate signals from layer  . Neuron feedforward (FF) activities are computed
. Neuron feedforward (FF) activities are computed  , where f is a non-linearity. Note, when we use
, where f is a non-linearity. Note, when we use  without a subscript, we refer to all neuron activities at all layers, and when we use
without a subscript, we refer to all neuron activities at all layers, and when we use 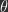 we are referring to all parameters in the model. At each training iteration
we are referring to all parameters in the model. At each training iteration  , where
, where  are the output layer FF activities.
are the output layer FF activities. 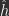 . One description of free energy, used in Alonso (2022), applied to standard MLP architectures is
. One description of free energy, used in Alonso (2022), applied to standard MLP architectures is .
.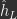 , the difference between
, the difference between  and the previous layer’s output
and the previous layer’s output  , and the magnitude of the activities. (Note it is also possible to use
, and the magnitude of the activities. (Note it is also possible to use 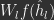 instead of
instead of  ).
).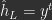 and
and  and to ignore the decay term (set
and to ignore the decay term (set  ). Further, it is standard to describe the outputs
). Further, it is standard to describe the outputs  as predictions of
as predictions of  . Under these conditions, F simplifies to
. Under these conditions, F simplifies to
 , at each layer
, at each layer 

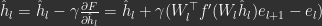 ,
, is the step size and f’ is the gradient of the non-linearity. We emphasize that these are only partial gradients, since these updates only use gradients of errors at layers
is the step size and f’ is the gradient of the non-linearity. We emphasize that these are only partial gradients, since these updates only use gradients of errors at layers  ,
, is the step size. Again, these updates only use local error information:
is the step size. Again, these updates only use local error information:  this update is a Hebbian-like learning rule that is the outer product of presynaptic activities
this update is a Hebbian-like learning rule that is the outer product of presynaptic activities  and post-synaptic error neuron activities,
and post-synaptic error neuron activities, 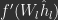 .
. 

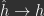 . This suggests IL-PC is able to reduce the loss because it is approximating BP and thus stochastic gradient descent (SGD). However, with a fully clamped output layer, as used by Whittington and Bogacz, this limit is only approximated late in training when the loss is small and activities only need to be altered slightly to reduce local errors. Early in training, however, when the loss is large, this approximation is worse. Yet IL-PC reduces the loss in a stable manner early in training, which raises the question of whether there is a better description of how IL-PC is reducing the loss. Indeed, recent theoretical works have emphasized the differences between IL-PC and BP/SGD, which we discuss more below (e.g., see Song et al. (2022), Millidge et al. (2022), and Alonso et al. (2022)).
. This suggests IL-PC is able to reduce the loss because it is approximating BP and thus stochastic gradient descent (SGD). However, with a fully clamped output layer, as used by Whittington and Bogacz, this limit is only approximated late in training when the loss is small and activities only need to be altered slightly to reduce local errors. Early in training, however, when the loss is large, this approximation is worse. Yet IL-PC reduces the loss in a stable manner early in training, which raises the question of whether there is a better description of how IL-PC is reducing the loss. Indeed, recent theoretical works have emphasized the differences between IL-PC and BP/SGD, which we discuss more below (e.g., see Song et al. (2022), Millidge et al. (2022), and Alonso et al. (2022)).  , given the parameters and the data
, given the parameters and the data  . Then the ‘M-step’ is performed, which updates
. Then the ‘M-step’ is performed, which updates  . This same procedure is equivalent to another two step algorithm, where one first minimizes a quantity known as variational free energy w.r.t.
. This same procedure is equivalent to another two step algorithm, where one first minimizes a quantity known as variational free energy w.r.t. 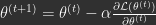

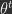 , where the gradient is computed using the parameters at the next training iteration, t+1. Generally, this gradient cannot be readily computed given known values at the current iteration t (e.g.,
, where the gradient is computed using the parameters at the next training iteration, t+1. Generally, this gradient cannot be readily computed given known values at the current iteration t (e.g.,  not known). However, it turns out the implicit SGD update is equivalent to the output of an optimization process known as the proximal operator, shown on the right hand side of the implicit SGD equation. The proximal operator sets the new parameters equal to the parameters that both minimize the loss,
not known). However, it turns out the implicit SGD update is equivalent to the output of an optimization process known as the proximal operator, shown on the right hand side of the implicit SGD equation. The proximal operator sets the new parameters equal to the parameters that both minimize the loss, 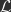 , and the norm of the change in parameters. It finds the parameters that best minimize the loss while remaining in the proximity of the current parameters. Therefore, the parameters updated with implicit SGD can be computed implicitly in terms of this optimization process/proximal operator.
, and the norm of the change in parameters. It finds the parameters that best minimize the loss while remaining in the proximity of the current parameters. Therefore, the parameters updated with implicit SGD can be computed implicitly in terms of this optimization process/proximal operator. , and reducing
, and reducing  (via the decay term). Fully or softly clamping the output layer activities and updating the weights to reduce local errors will yield a new input/output mapping that reduces the loss given the same input, which is shown intuitively in the figure above. Second, reducing
(via the decay term). Fully or softly clamping the output layer activities and updating the weights to reduce local errors will yield a new input/output mapping that reduces the loss given the same input, which is shown intuitively in the figure above. Second, reducing  and
and  and reduce
and reduce  , just like implicit SGD. Importantly, there are differences between explicit and implicit SGD. For example, they typically do not move parameters through parameter space along the same path, and implicit SGD is far less sensitive to learning rate than explicit SGD. For details see the paper and/or summary referenced below.
, just like implicit SGD. Importantly, there are differences between explicit and implicit SGD. For example, they typically do not move parameters through parameter space along the same path, and implicit SGD is far less sensitive to learning rate than explicit SGD. For details see the paper and/or summary referenced below.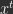 to target output
to target output 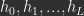 that generate predictions/reconstructions of the data and other hidden representations. In probabilistic terms, we want to learn a generative model
that generate predictions/reconstructions of the data and other hidden representations. In probabilistic terms, we want to learn a generative model 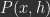 , that we can sample from and use to perform inference. Unlike more standard achitectures for this task, like variational autoencoders, PC networks do not use an encoder that directly maps
, that we can sample from and use to perform inference. Unlike more standard achitectures for this task, like variational autoencoders, PC networks do not use an encoder that directly maps  . Instead PC networks compute
. Instead PC networks compute 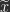 , are presented where noise is added to the data or certain elements of the data are removed/set to 0. The model must return the uncorrupted version of the data (i.e., denoise or fill in missing elements). That is, we want the model to be able to learn the mapping
, are presented where noise is added to the data or certain elements of the data are removed/set to 0. The model must return the uncorrupted version of the data (i.e., denoise or fill in missing elements). That is, we want the model to be able to learn the mapping  . Salvatori et al. (2021) recently showed that PC networks trained with IL can perform auto-associative tasks and outperform other standard auto-associative models like modern Hopfield networks, and PC networks are able do so on high-dimensional image vectors.
. Salvatori et al. (2021) recently showed that PC networks trained with IL can perform auto-associative tasks and outperform other standard auto-associative models like modern Hopfield networks, and PC networks are able do so on high-dimensional image vectors. 